 Keep ‘em separated Get better maintainability in web projects using the model-view-controller pattern
Keep ‘em separated Get better maintainability in web projects using the model-view-controller pattern

original address:Keep ‘em separated: Get better maintainability in web projects using the model-view-controller pattern (opens new window)
MVC is an old pattern, but it's still relevant to web apps.
From a user’s perspective, a software application, whether it’s mobile, desktop, or web based, is something that you interact with and it does stuff. But from a developer’s perspective, there’s a lot of separate actions that occur: the user interacts with a UI, the program takes that input and performs some tasks on the data, and the data feeds back into the user interface. That’s the technical version of doing stuff.
Software engineers use a design pattern to build this separation of concerns into their software architecture. The model-view-controller (MVC) was created in the late 1970s by Trygve Reenskaug when working on Smalltalk. Though it is an older, pre-web design pattern, it is ubiquitous in modern applications. The pattern can be found on the web in both backend and frontend applications, on mobile, desktop, and more.
The pattern’s name references models, views, and controllers. These are the core building blocks in MVC apps. Each of these components has a specific role and behavior. Let’s take a closer look at the use and implementation of this pattern.
# The basics of the pattern
Models provide access and storage for the application data. Typically a model represents a database table. However, models can represent data in any form, they may represent data held in memory, cache, or even a third-party service. Models implement methods to access or modify the data, most commonly these are create, read, update, and delete (aka CRUD) operations.
Views transform the application data in memory to user interface elements. They may also just serialize the data or transform the data to other user interface representations like the native user interface in mobile apps.
Controllers are the glue of the pattern. They are the entry point of the pattern and make models and views work together. All operations are first handled by controllers. Controllers offer high-level actions with required data inputs. Upon an action call, they handle action on the data, pass the data to the models, and then pass the models or the data to views for rendering. All user actions in the application are passed through the controller. The controller decides what should happen next.
# MVC on the web
In web applications, controllers handle HTTP requests and responses. They are responsible for pulling the right data from the requests, performing the business logic with error handling, and returning the correct HTTP status and data in the HTTP response. Controllers are typically stateless and own the stateful instances of the models and views. In web applications, controllers create model and view instances when a request comes in or when an action is called, but they don’t own or call other controllers.
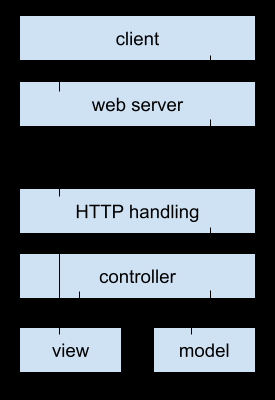
Models are responsible for holding the state of the application. In other words this means models store and do low-level work with the data, it can be a class or an object with methods and members holding data or it can be a wrapper of a third-party API. Models frequently have an asynchronous API because they work with low-level asynchronous operations like working with the database, reading from a file, or communicating over a network. Models can work with other models, call them, and use their methods. One model may create composite and more complex operations based on the functionality of other low-level models. As an example, a model may pull some data using another model that wraps a third-party service and store that data into a database table using a model for that table. Models should not work on their own. They don’t call controllers or views or hold any references to them.
Views render the data in a web browser or mobile application. Web application views are stateless and they can be as simple as JSON serializers or as complex as HTML templating engines. Views take data in the form of model instances or custom objects and translate the data into the requested form. Sometimes web applications can support multiple forms of data representation driven by the HTTP Accept header. In MVC, this could just mean employing a different serializer for JSON or XML or a templating engine for the data. Views may call other views to render different types of objects or sub-objects. Views may receive model instances and work with model APIs. However, patterns where a view would directly manipulate data in the model is not recommended. It is always and only the responsibility of the controller to call functions on models that could manipulate the state of the application. Avoid the possibility of this pattern by creating a proxy object that holds the data ready to be rendered in the controller, initializing these objects with data from the models and passing this proxy object down to a view. This way, the controller stays in control of the view’s access patterns and data exposed to the view.
# Interfaces
Each component of the MVC design pattern has an interface. This interface provides a way to interact with the objects. In an MVC application on the web, this interaction starts with the controllers. A web server typically interacts with a controller after it receives an HTTP request. The requests are first processed by lower levels of framework or web server logic. This processing handles parsing and deserializing the request and calling a method on the controller.
The web MVC controllers typically implement methods that represent operations provided by the HTTP protocol: GET, POST, PUT, and DELETE. But these HTTP methods don’t need to map to a single method on the controller. The mapping is controlled by routing logic that provides additional options to invoke the right controller method based on the paths or parameters provided in the request URL. In an app using a database, some controllers might implement methods like list or index to wrap model calls and display lists of records with their ids and then a get method to get a specific record based on its id.
For retrieving records, the call comes from controllers to models. In web application frameworks like Ruby on Rails or Django, you may find models providing or implementing several find methods. These methods accept a record id and or other parameters that are passed to queries to lookup specific records. To create records, the models implement create factory methods or allow instancing the model. The models are instanced via class constructor and their properties are set through the constructor parameters or through setter methods defined on the model. The models sometimes wrap specialized record creation into class or static factory methods. These factory methods can provide a nice interface allowing you to quickly understand how the model is instanced in the application code or in tests.
# Implementation pitfalls
The most common pitfall when implementing new MVC apps is the lack of respect towards the separation of concerns presented and enforced by the pattern. Developers sometimes decide to cut corners and skip the separation of concerns in order to be quickly done with their changes.
# Too smart views
The views in MVC web applications are responsible for translating internal data structures into presentable text format like XML or HTML. Some logic is necessary to do so. You can iterate over arrays of records using loops. You can switch between different types or sections of content for display using branching. Views by nature contain a large amount of markup code. When the markup code is mixed with looping and branching logic, it is much harder to make changes to it and visualize the results. Too much branching or conditions in the view also make the markup hard to read. Spaghetti only works as food, not code. There are two tools that help with this problem: helper functions and view file splitting.
Helper functions are a great way to isolate logic that may be called multiple times, shared, or re-used between views and let you follow DRY principles (opens new window). Helpers can be as simple as providing an element class name based on some input or as complex as generating larger pieces of the markup.
File splitting is another powerful approach that can improve code readability and maintainability. Every time a view grows too large or too complex, you can break it down to smaller pieces where each piece does only a single thing. Just the right amount of view file splitting can make a big difference in organization of the project.
Overapplying helper functions or view file splitting can also lead to problems, so it is best to drive changes when there’s a reason—and that reason should be a too complex view.
# Heavy controllers
Controllers are responsible for implementing actions coming from the frontend, the UI, or the API of the application. For many developers, it becomes tempting to implement data processing logic in the controllers. Sometimes you may see database queries built directly in the controllers and the results stitched together with other data in some complex logic and then the results returned to the views or serializers. Other instances of this problem look like third-party API calls made directly from controllers and the results adjusted or mixed with other data from the local models and returned back to the client. Both of these are cases of heavy controllers.
The controllers should be light on logic. They should process input parameters and pass the adjusted input down to the models. The controllers take the inputs, choose and call the right models and their methods, retrieve the results, and return the results in the right format back to the client. Heavy lifting with data shouldn’t be done directly in the controller methods to avoid code complexity problems and issues with testing.
# Light models
Models are built to manage, hold and represent the application data. Every time the application needs to work with the data, it should reach into some model. Sometimes application developers decide to perform data manipulation in controllers, which makes the controller code more complex and creates code maintenance problems. Since models work with data, any incorrect logic on the models may corrupt the data. This is why the models should have the highest test coverage out of the entire app. Well-implemented models are very easy to unit test.
Application logic that reads and writes data should be concentrated on the related models. For example, if the data queries are spread all over the controller code then it is harder to get good model test coverage. When the developers debug issues like slowness in the database, they may not see all queries performed against a table right away so it may take them longer to optimize the queries and implement better indexing.
Another example can be an interaction with third-party services. Applications frequently require communication with cloud and data providers and this is done through asynchronous calls and APIs. These methods return data that gets processed, altered and saved in the application. It is beneficial to treat these interactions with third-party APIs as model logic and place it on the respective model. This puts the third-party logic to a specific place in the app where it can be quickly covered with integration tests.
# Conclusion
The MVC pattern was developed to separate concerns and to keep the application code highly organized. Frameworks like Ruby on Rails that are built on top of this pattern and reap the benefits of strict naming and placement. Closely following this pattern makes projects based on it easier to understand, maintain, and test. Correct usage of its rules reduces developers’ mental load and speeds up any bug fixing or new feature development. Long live the model-view-controller!