 Serverless scales well, but most databases don’t
Serverless scales well, but most databases don’t

original address: Serverless scales well, but most databases don’t (opens new window)
The benefits that come from serverless computing can be lost if you have to spend your time provisioning hardware for your database.
# SPONSORED BY MONGODB
For applications aiming for high availability without the hassle of managing infrastructure issues, serverless computing has emerged as the next level of hardware abstraction.
Cloud computing and containers virtualized the physical servers that web and mobile apps ran on, but you still needed to provision those resources and manage how they scaled. While serverless doesn’t eliminate the server (obviously) it does mean that you don’t have to think about how your infrastructure will have to scale to support your application’s fluctuating traffic, allowing for faster development cycles by lessening the management burden.
Serverless technology is most commonly implemented via serverless functions, or functions as a service (FaaS), which are used to run business logic in stateless containers. But if you’re building an application that needs to persist data, you’ll need to connect your serverless functions to a database.
The benefits that come from serverless computing can be lost if you have to spend your time provisioning hardware or worrying about capacity planning and management as your application scales. In fact, traditional databases, (even fully-managed DBaaS), are generally not well-suited for managing the frequent yet disposable requests that come from serverless functions.
Fortunately, there are some databases that can handle the sort of workload that a serverless application produces, as they themselves are built to operate in a serverless manner. In this article, we’ll dive into the perils of working with a database that isn’t serverless and just how much difference the right database makes for running serverless applications.
# What is serverless?
With all the buzz about serverless, it’s a good idea to step back and make sure that we’re talking about the same thing. Serverless is an umbrella term. At its core, it’s a computing model where you don’t need to think about the underlying infrastructure: you don’t provision resources, you don’t manage scaling, and you don’t worry about high availability. All that happens automatically.
With serverless, you only pay for resources that you use while your requests are being handled. When demand increases during periods of high traffic, the resources available scale accordingly. When traffic drops, you no longer pay for those resources. Alternatively, a pre-provisioned cloud-based service can run up your bill sitting idle and listening for requests. You can still encounter high bills with serverless computing, but only because you’ve had unexpectedly high usage. Serverless has a lot of benefits for applications with variable or sparse workloads. Think about a betting company that allows live wagers during the World Cup, as an example. During a match, bets may come in at any time, but you can assume that the number of new bets will spike when one team scores. Unfortunately you can’t predict when a goal is going to be scored. With serverless, the infrastructure behind the betting application would instantly auto-scale to support the traffic. In the absence of auto-scaling, you would need to manually monitor your resource consumption to determine when it was necessary to scale up — assuming you have the available resources to do so.
Serverless databases (opens new window) essentially work the same way. When you send them data, the databases automatically scale to handle increased connections and storage requirements. You pay for the read/write traffic and the storage that the data occupies. That’s it.
# The challenges with traditional RDBMS and serverless computing
When you mix a serverless compute platform with a traditional relational database (RDBMS) (opens new window), you’re likely to run into some issues. The most obvious (although not limited to relational databases alone) are around provisioning infrastructure resources. While you’re saving time by using serverless computing, you still need to worry about infrastructure for your database. Even if the database is hosted on a managed platform, you still need to provision those resources — the “managed” part refers to the infrastructure that it’s hosted on, not necessarily the resources available. Databases will grow over time as new data is stored, so your storage resources, in addition to compute, also need to be able to grow with it.
Another common challenge is the risk of overwhelming the database with too many connections. In a standard database interaction, a service or application opens a connection to a database, maintains it to read and write data, then destroys the connection when finished. Serverless functions may spin up a new connection for every request, creating dry connections: open connections that aren’t sending or receiving data, but add to the number of total open connections and can potentially block new connections. Choosing a serverless database eliminates this challenge entirely and will simply scale (up or down) in accordance with your application needs without any work required on your part.
You can pool connections (opens new window) to improve performance and avoid running dry connections, but you still risk read/write conflicts if multiple connections are accessing the same data. A database built for serverless typically has pooling or some form of load balancer built in to help mitigate this problem.
# Document-model databases work better with serverless
The biggest drawback to selecting a relational database for your serverless architecture is the structural rigidity of the database schema. In an RDBMS, each record stored must conform to the structure that the table implements without exception. All data must be written to a table, and every table has a set number of columns. If you have data that has values that don’t fit into any of those columns, you’ll need to add a new column. Each piece of data already entered into the table will require an update to include a value for that column and indexes will need to be refactored.
The cost of schema changes makes it harder to iterate on and evolve your database structure alongside your application logic. You lose out on one of the core values of serverless —– speed to market.
Instead, opting for a document model database deployed on the cloud, like MongoDB Atlas lets you store data as it comes to you. Whereas relational databases impose strict data structures, document model databases define the structure of each document separately, giving you a great deal of flexibility while you develop.
For fast moving products, change happens often. If you’re locked into a specific data schema, that limits the kinds of changes that you can make. Document databases allow any new document structure you want to apply to exist alongside all previous structures. If you need to adjust existing records, you can backfill data or modify the structure as a separate process. This makes it easy to iterate on and evolve your data model as you develop.
# Achieving serverless-style scalability from a database
Beyond just the benefits of the data model, MongoDB Atlas also removes much of the pain associated with provisioning and scaling infrastructure. Our fully managed data platform makes it easy for you to get the database resources you need when you need them, with automatic, elastic scaling to take the burden off of development teams. This is especially important when working with serverless compute services (or any serverless architecture for that matter) when you need your database to be reactive to unexpected spikes in traffic.
This type of scaling can be achieved with an Atlas dedicated cluster with compute and storage auto-scaling enabled, which will give you more control over setting minimum and maximum scaling thresholds, or you can opt to deploy a serverless database. A serverless database in Atlas, referred to as a serverless instance, is an on-demand endpoint that scales automatically to meet your application needs without any upfront provisioning or capacity management required. They are based on an operations-based pricing model that charges only for the resources and storage used and will scale down to zero if there is no traffic—giving you the full benefits (opens new window) of building on top of serverless infrastructure.
However, as with serverless computing, a sudden spike in traffic can sometimes lead to a surprisingly large bill. To minimize this sticker shock, we’ve implemented a tiered pricing system (opens new window) for read operations in which each tier is progressively less expensive. You still pay for what you use, but you’ll pay less for that traffic the more traffic you get.
# Getting started with a serverless database in MongoDB Atlas
Because all infrastructure is provisioned and all scaling is handled, getting started with a serverless database is a matter of naming the database instance and pointing it to your cloud provider of choice (available in regions on AWS, Google Cloud and Azure). Seriously:
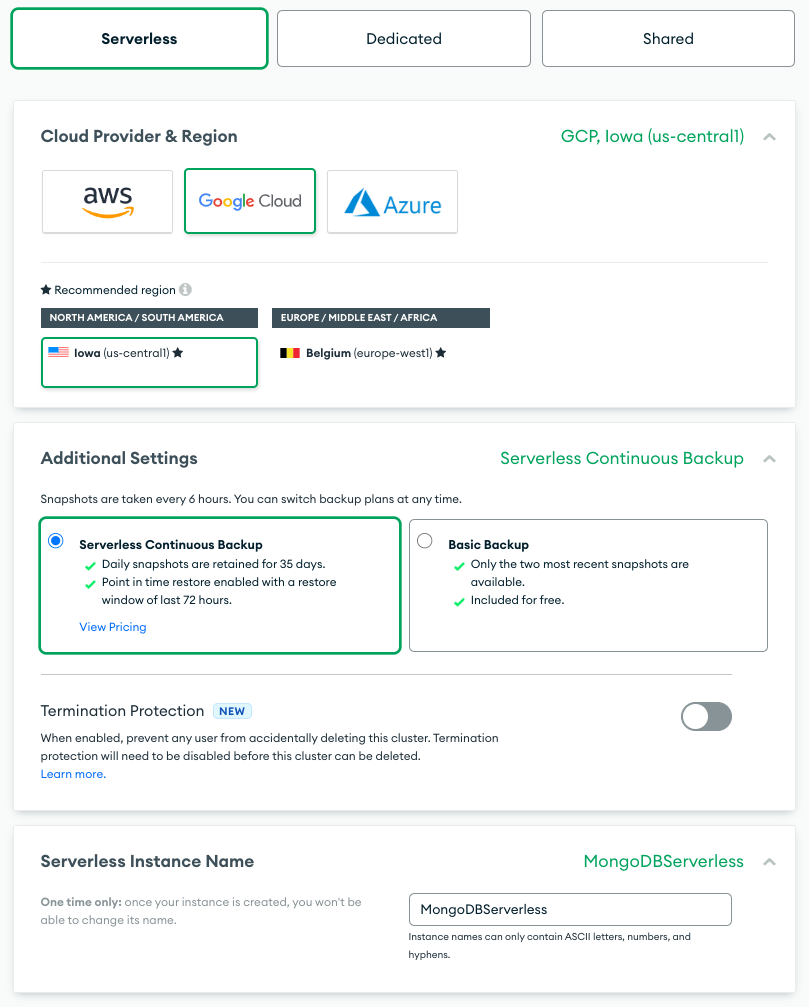
All you need to do is pick your provider, region, and desired backup option, then give your instance a name you’ll use to refer to it in your application. That instance name is probably the most important part of this setup; you’ll need to include it in the database connection string that opens a connection to a database, so make it memorable and manageable.
In contrast, creating a database on a dedicated server requires you to select the infrastructure requirements and a host of other configuration options that have been abstracted in serverless, helping to save you time.
“Thanks to Atlas serverless instances we are spending less time wrestling with infrastructure and configuration and more time developing solutions for our customers.” – CEO, Small Business Computer Services Company.
# Build full-stack serverless applications with MongoDB Atlas + Google Cloud Run
If you’re looking to get started with a serverless compute and database stack, we’ve found good results running MongoDB Atlas with Google Cloud Run (opens new window). It’s a fully-managed serverless solution that performs seamlessly with our database instances.
Cloud Run’s automatic scalability, combined with MongoDB Atlas’s fully managed and highly available database, allows for a seamless and cost-effective way to handle incoming traffic. As Cloud Run automatically spins up additional containers to handle the load, your serverless database will also provide more resources to handle the database load. This ensures that your application is always able to handle incoming traffic, even during periods of high and unexpected usage, without you having to worry about managing the underlying infrastructure. So you can focus on developing and deploying your application, instead of worrying about maintaining servers or databases.Both Cloud Run and MongoDB Atlas are pay-per-use services, which means that you only pay for the resources you actually use. Depending on your use case, this may help you save on cost as you are not paying for resources that you don’t need.
Finally, Cloud Run’s stateless and event-driven nature and MongoDB Atlas’s automatically scaling and highly available database make them a great fit for a wide variety of use cases, from simple web applications to complex microservices architectures. Developers can take full advantage of serverless technology across the entire stack, making their development process more streamlined and cost-effective.
# Move fast and don’t worry about infrastructure
For individuals or organizations looking to get a cloud-based application up and running quickly without having to worry about provisioning and scaling infrastructure, serverless has emerged as a solid option. But you could miss out on the full benefits of serverless if part of your stack — your databases — aren’t optimized for flexibility and scale.
If you’re looking to improve your efficiency and take advantage of the added benefits of a serverless database, sign-up for MongoDB Atlas on Google Cloud Marketplace (opens new window) to try Atlas serverless instances today. After signing up and completing the setup wizard, you’ll be ready to start storing data within minutes. If you’re not quite ready for that, you can also visit our website (opens new window) to learn more about how to build serverless applications with MongoDB Atlas to make sure you’re prepared when your next project arises.