 Scrapy框架初识
Scrapy框架初识

# (1)Scrapy模块安装
scrapy支持Python2.7和python3.4以上版本。
python包可以用全局安装(也称为系统范围),也可以安装在用户空间中。
Windows 一.直接安装 1.在www.lfd.uci.edu/~gohlke/pyt… (opens new window) 下载对应的Twisted的版本文件 2. 在命令行进入到Twisted的目录 执行pip install 加Twisted文件名
3.执行pip install scrapy 二.annaconda 下安装 (官方推荐) 1.安装conda conda旧版本 docs.anaconda.com/anaconda/pa… (opens new window) 安装方法 blog.csdn.net/ychgyyn/art… (opens new window) 2. 安装scrapy conda install scrapy
# (2)Scrapy框架简介
Scrapy是纯Python开发的一个高效,结构化的网页抓取框架。
# Scrapy是个啥?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。 Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 Scrapy使用了Twisted 异步网络库来处理网络通讯。
# 我们为啥要用这玩意呢?
1.为了更利于我们将精力集中在请求与解析上。 2.企业级的要求。
# (3)运行流程
(只要提到框架,就要重视它的运行流程/逻辑顺序)
# 引入:
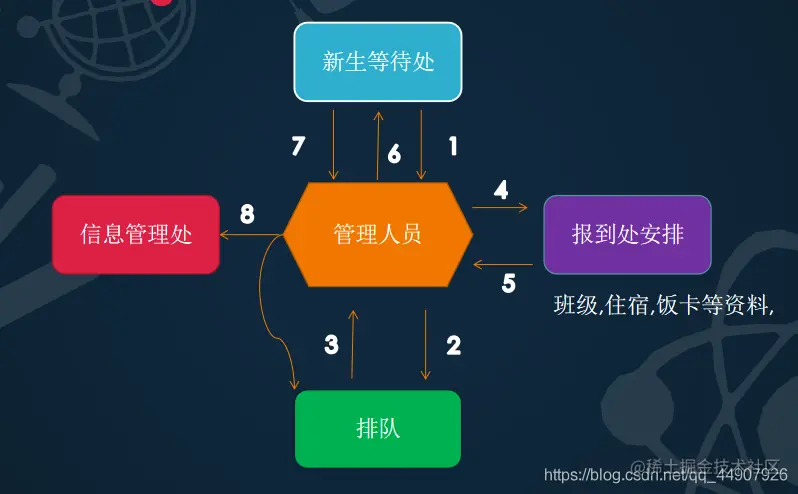
注意:图中的弧线的意义: 如果,在小明拿到信息核对之后发现这些不是自己所需的,那么,小明就会告诉管理人员,这些不是我所要的,我要重新请求一下别的东西,然后管理人员就就会将小明进行重新排队!!!
# 1.进入正题:
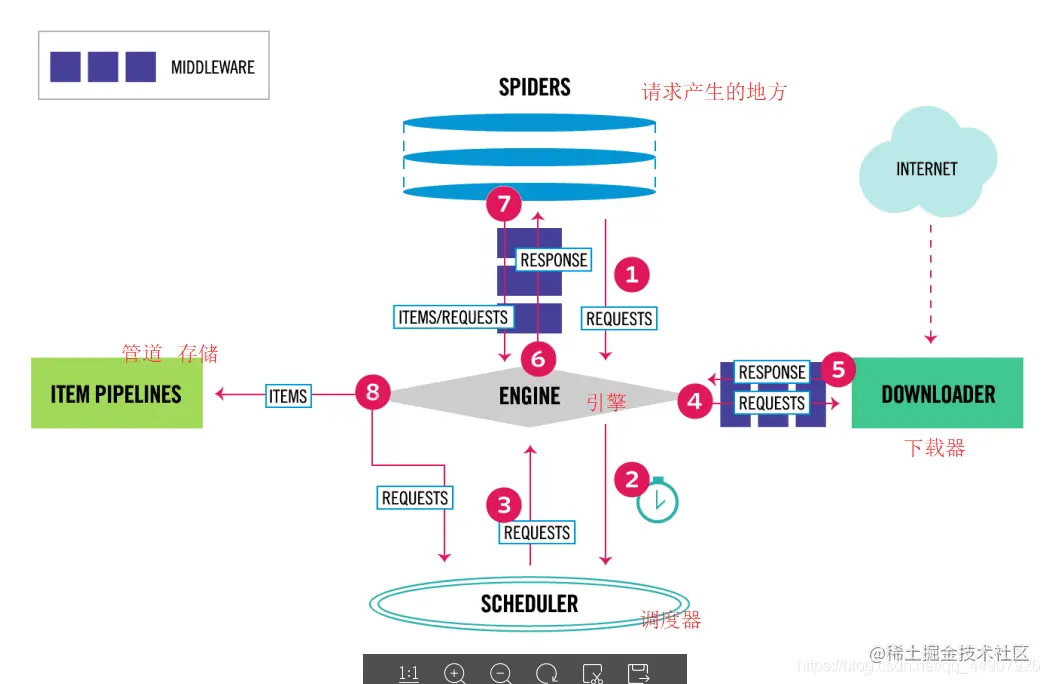
数据流: 上图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流(由红色的箭头显示。) Scrapy中的数据流由执行引擎控制,流程如下:
首先从网页爬虫获取初始的请求 将请求放入调度模块,然后获取下一个需要爬取的请求 调度模块返回下一个需要爬取的请求给引擎 引擎将请求发送给下载器,依次穿过所有的下载中间件 一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。 引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件 爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎 引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求 该过程重复,直到调度程序不再有请求为止。
# 中间件介绍:
(1)下载中间件 下载中间件是位于引擎和下载器之间的特定的钩子,它们处理从引擎传递到下载器的请求,以及下载器传递到引擎的响应。 如果你要执行以下操作之一,请使用Downloader中间件: 在请求发送到下载程序之前处理请求(即在scrapy将请求发送到网站之前) 在响应发送给爬虫之前 直接发送新的请求,而不是将收到的响应传递给蜘蛛 将响应传递给爬行器而不获取web页面; 默默的放弃一些请求
(2)爬虫中间件 爬虫中间件是位于引擎和爬虫之间的特定的钩子,能够处理传入的响应和传递出去的item和请求。 如果你需要以下操作请使用爬虫中间件: 处理爬虫回调之后的请求或item 处理start_requests 处理爬虫异常 根据响应内容调用errback而不是回调请求
# 2.各个组件介绍:
Scrapy Engine(引擎) 引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。
scheduler(调度器) 调度程序接收来自引擎的请求,将它们排入队列,以便稍后引擎请求它们。
Downloader(下载器) 下载程序负责获取web页面并将它们提供给引擎,引擎再将它们提供给spider。
spider(爬虫) 爬虫是由用户编写的自定义的类,用于解析响应,从中提取数据,或其他要抓取的请求。
Item pipeline(管道) 管道负责在数据被爬虫提取后进行后续处理。典型的任务包括清理,验证和持久性(如将数据存储在数据库中)
# 🔆In The End!
# 👑有关于Me
个人简介:我是一个硬件出身的计算机爱好者,喜欢program,源于热爱,乐于分享技术与所见所闻所感所得。文章涉及Python,C,单片机,HTML/CSS/JavaScript及算法,数据结构等。
从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你!
认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多技术文哦~